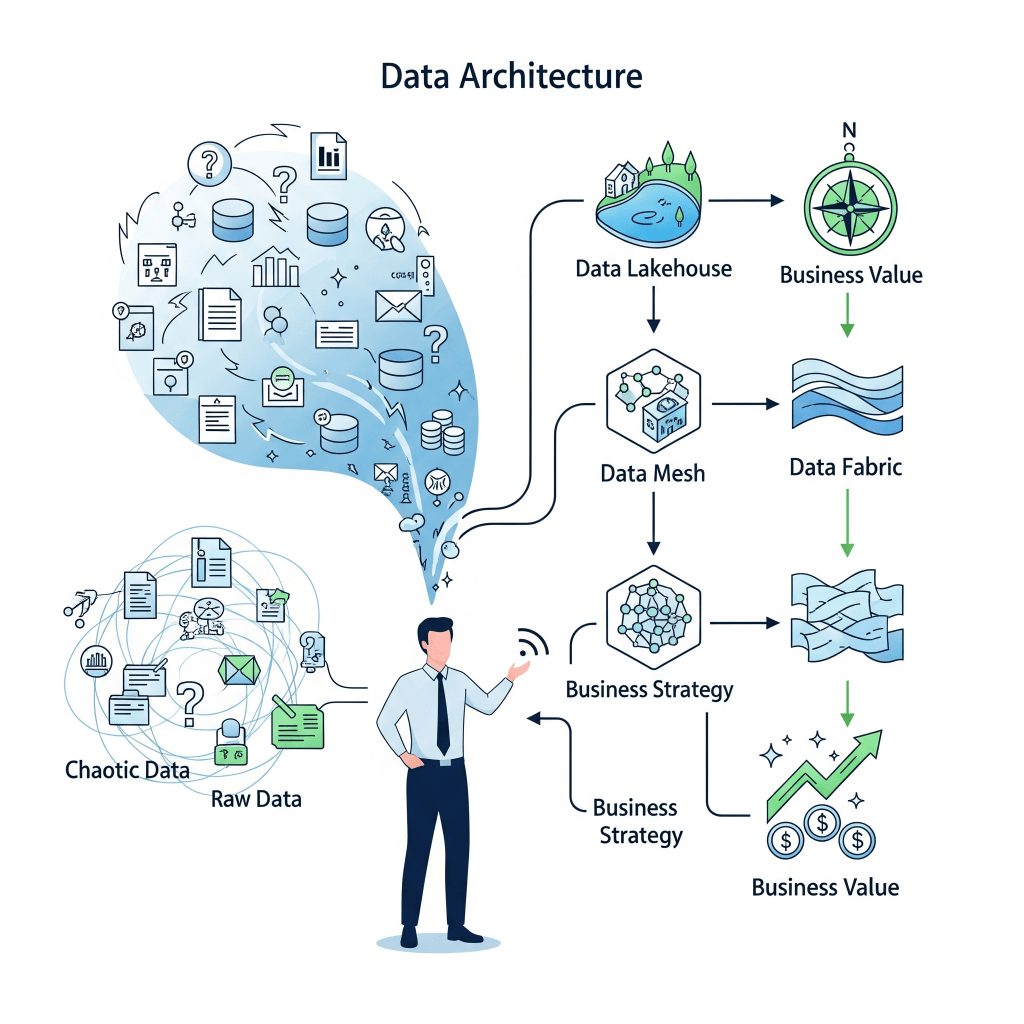
À l’ère du numérique, la donnée n’est plus un simple sous-produit des opérations ; elle est devenue l’actif le plus stratégique de l’entreprise. La capacité à collecter, traiter, exploiter et gouverner les données pour en extraire de la valeur est ce qui distingue les leaders de marché des suiveurs. Cependant, sans une fondation solide (structurée et évolutive), toute initiative data est vouée à l’échec. Cette fondation, c’est l’architecture Data.
En tant qu’architecte d’entreprise, mon objectif est de démystifier les concepts de l’architecture data et de fournir une vision claire de son rôle essentiel dans la transformation numérique. Cet article montre également le rôle et les responsabilités du chef d’orchestre de cette architecture : l’architecte data.
Pour cela, nous nous appuierons sur des cadres de référence reconnus tels que TOGAF pour la démarche de raisonnement, IT4IT pour le fonctionnement du département IT, et les capacités métiers pour décrire les besoins du business, afin de garantir une approche structurée et alignée avec les meilleures pratiques d’architecture d’entreprise.
Ce que nous allons voir dans cet article :
- Fondements conceptuels de l’architecture Data moderne
- Évolution des paradigmes architecturaux : Du centralisé au distribué
- L’architecture Data Lakehouse
- Master Data Management (MDM)
- Le Data Catalog d’entreprise
- Le rôle stratégique de l’architecte Data
- Conclusion
Fondements conceptuels de l’architecture Data moderne
Avant de plonger dans les détails techniques des différents paradigmes de l’architecture data, il est impératif de comprendre les deux piliers conceptuels qui sous-tendent toute démarche : l’alignement stratégique et la gouvernance des données.
L’Alignement Stratégique
Historiquement, l’architecture data était perçue comme une fonction de support purement technique, généralement concentrée sur la modélisation des bases de données. Son objectif principal était d’assurer le stockage et la disponibilité des données pour des applications transactionnelles ou des rapports prédéfinis. Cette vision est aujourd’hui obsolète.
L’architecture data est intrinsèquement liée à la stratégie globale de l’entreprise. Elle n’est plus une conséquence, mais une composante active de la planification stratégique. Selon le framework TOGAF, toute architecture doit commencer par une « Architecture Vision » (Phase A de l’ADM) qui découle directement des objectifs métiers (Business Goals, Drivers, and Objectives).
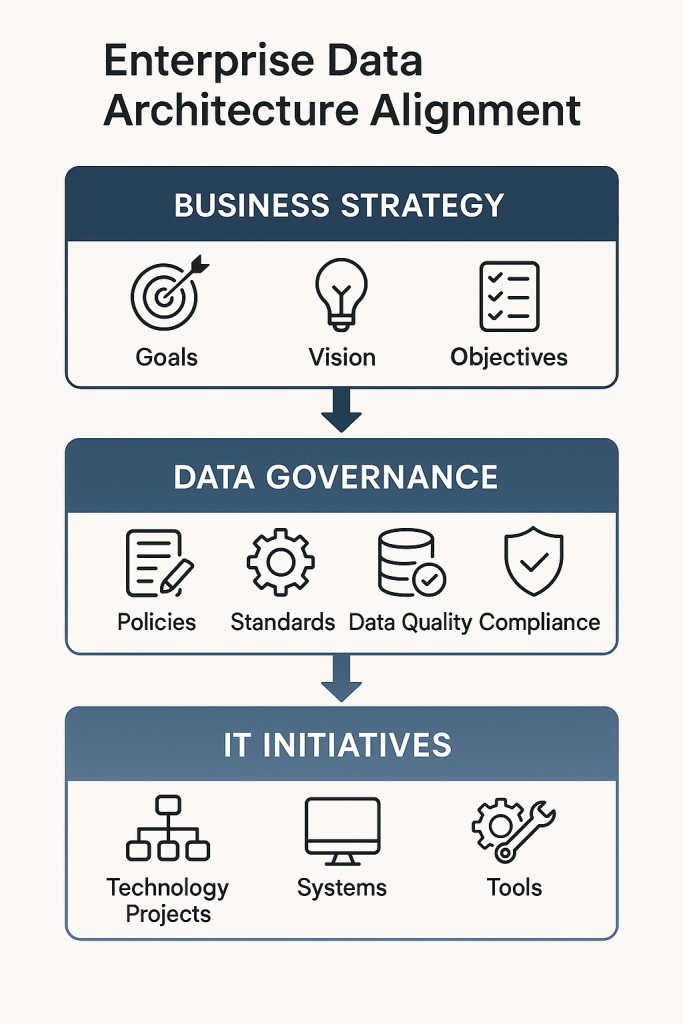
Cela implique que l’architecte data doit :
- Comprendre en profondeur la stratégie de l’entreprise : Quels sont les objectifs de croissance ? Quels nouveaux marchés en prévision ? Quelle expérience client souhaite-t-on offrir ? …
- Traduire les objectifs métiers en capacités data : Par exemple, l’objectif « personnaliser l’expérience client en temps réel » pourrait se traduire par la nécessité d’une capacité de streaming de données, d’un moteur de recommandation et d’un profil client unifié à 360°.
- Garantir la traçabilité : Chaque composant de l’architecture data doit pouvoir être justifié par sa contribution directe ou indirecte à une capacité métier et, in fine, à un objectif stratégique.
- Assurer le respect des règles de conformité : Chaque composant de l’architecture data doit garantir et justifier le respect des contraintes légales, par exemple comme le RGPD.
L’alignement stratégique assure que les investissements data ne sont pas des coûts techniques, mais des investissements « créateurs de valeur« , mesurables et alignés sur la trajectoire de l’entreprise.
La gouvernance des données
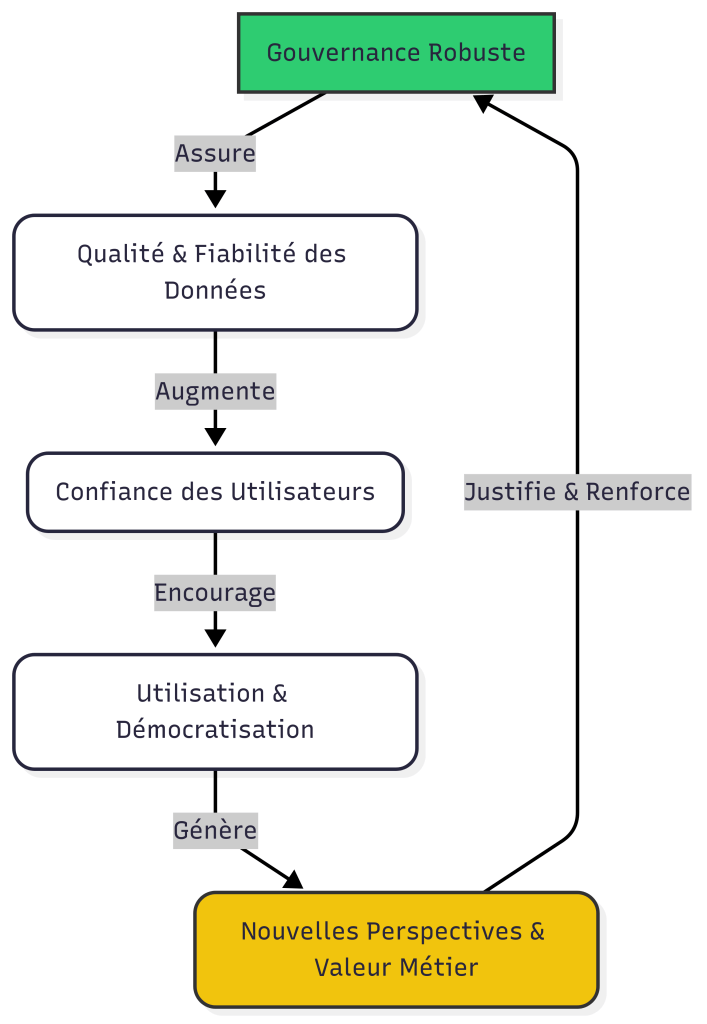
La gouvernance des données a longtemps été perçue comme un frein, une contrainte bureaucratique imposée. Dans une architecture moderne, elle devient un catalyseur de valeur et un prérequis à la démocratisation de la donnée.
Une gouvernance efficace vise à garantir que les données sont fiables, compréhensibles, sécurisées et facilement accessibles pour ceux qui en ont le droit. C’est pourquoi une gouvernance dite « moderne » est indispensable pour assurer la protection des données des activités critiques d’une entreprise ou d’une administration.
Les composantes clés de cette gouvernance moderne incluent :
- La qualité des données (Data Quality) : Mettre en place des processus et des outils pour mesurer, surveiller et améliorer la qualité des données (complétude, exactitude, fraîcheur).
- La gestion des métadonnées (Metadata Management) : Centraliser les définitions, le data lineage et le contexte métier des données dans un catalogue d’entreprise pour les rendre découvrables et compréhensibles.
- La sécurité et la conformité : Définir et appliquer des politiques d’accès granulaires (qui a le droit de voir quoi ?) et assurer la conformité avec les réglementations. Une gestion des risques pour déterminer les mesures de protection adéquates est une bonne approche à mettre en place dans un premier temps.
- La gestion du cycle de vie (Data Lifecycle Management) : Définir des règles pour l’archivage et la suppression des données afin d’optimiser les coûts et de rester en conformité.
Une gouvernance bien pensée transforme la donnée brute en un actif fiable et certifié, augmentant la confiance des utilisateurs et accélérant la prise de décision.
Évolution des paradigmes architecturaux : Du centralisé au distribué
L’histoire de l’architecture data est marquée par une tension constante entre centralisation et décentralisation des données. Les architectures monolithiques traditionnelles, bien qu’efficaces pour certains cas d’usage (comme dans des contextes de petites entreprises, par exemple), ont montré leurs limites face aux exigences d’agilité, de scalabilité et d’autonomie des systèmes de plus grandes ampleurs.
Des Data Warehouses monolithiques aux écosystèmes agiles
Le modèle traditionnel du Data Warehouse d’entreprise reposait sur une centralisation extrême : une équipe IT unique était responsable de l’ingestion (ETL), de la modélisation et de la mise à disposition des données pour toute l’entreprise.
Limites du modèle centralisé :
- Goulot d’étranglement organisationnel : L’équipe IT centrale devient un point de passage obligé pour toute nouvelle demande, créant des délais importants.
- Manque de contexte métier : L’équipe IT, éloignée des domaines métiers, a du mal à comprendre la signification et les subtilités des données qu’elle manipule.
- Scalabilité limitée : L’architecture est souvent rigide et difficile à faire évoluer pour intégrer de nouvelles sources de données ou de nouveaux cas d’usage.
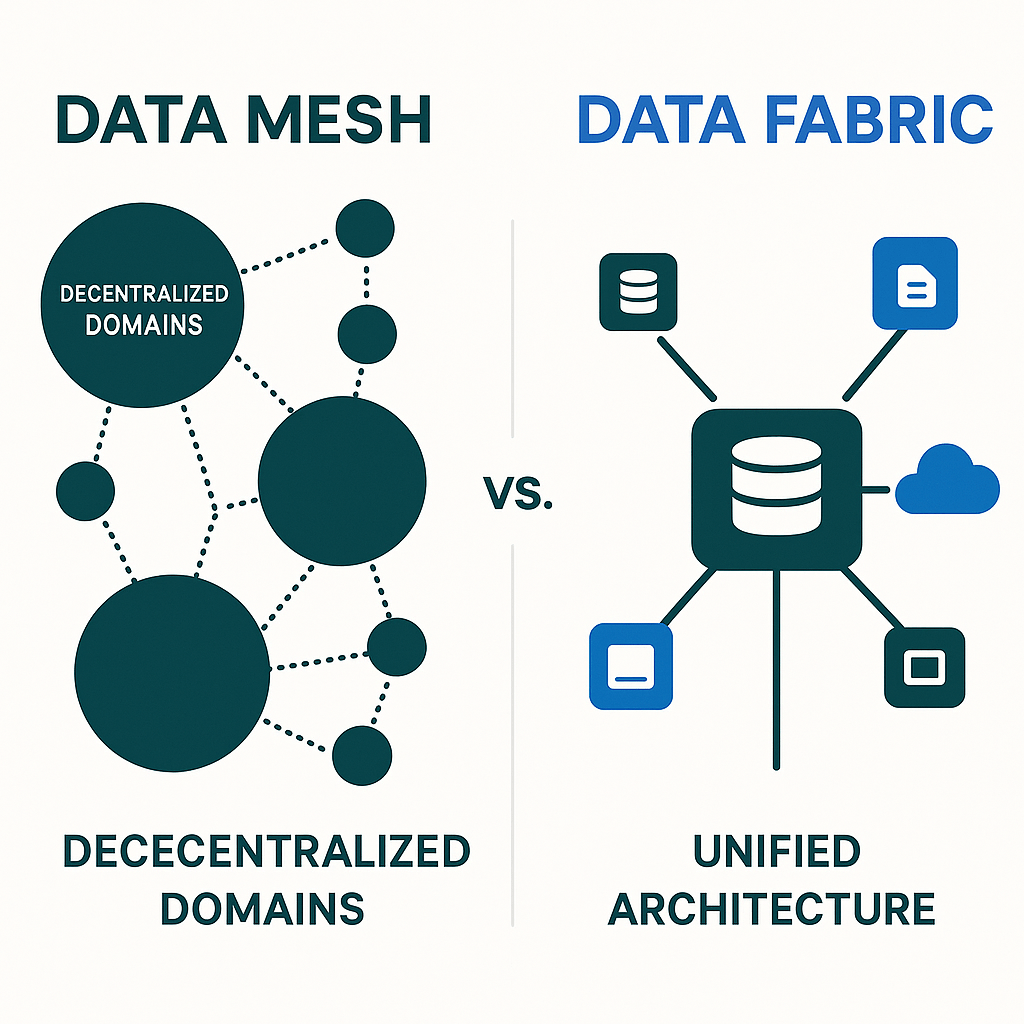
Face à ces limites, deux nouveaux paradigmes ont émergé pour promouvoir une approche plus distribuée, agile et orientée métier : le Data Mesh et le Data Fabric.
Le Data Mesh
Le Data Mesh, conceptualisé par Zhamak Dehghani, propose un changement de paradigme radical basé sur quatre principes fondamentaux :
- L’appropriation des données par les domaines métiers (Domain Ownership) : Les équipes qui connaissent le mieux les données (marketing, finance, logistique) deviennent responsables de leurs données de bout en bout. Elles les traitent non pas comme un sous-produit, mais comme un produit à part entière (« Data as a Product »).
- Les données comme un produit (Data as a Product) : Chaque domaine expose ses données via des interfaces claires, documentées et fiables. Ces « produits data » doivent être découvrables, compréhensibles, fiables et sécurisés, tout comme un produit logiciel.
- La plateforme de données en libre-service (Self-Serve Data Platform) : Pour permettre aux domaines de gérer leurs produits data sans réinventer la roue, une équipe de plateforme centrale fournit des outils et des services standardisés pour le stockage, le traitement, la gouvernance et le monitoring.
- La gouvernance fédérée (Federated Computational Governance) : La gouvernance n’est plus un diktat centralisé. Une équipe de gouvernance fédérée, composée de représentants des domaines et de l’IT, définit les règles et standards globaux (interopérabilité, sécurité), tandis que les domaines sont autonomes pour leur mise en œuvre.
Le Data Mesh transforme l’organisation en un écosystème de producteurs et de consommateurs de données autonomes mais interconnectés.
Remarque :
Ne pas confondre DaaP et DaaS (Data as a service) :
| Caractéristique | DaaS (Data as a Service) | DaaP (Data as a Product) |
|---|---|---|
| Objectif | Faciliter l’accès et la livraison de données. | Fournir une proposition de valeur, autour de la donnée (autonome et fiable) pour répondre à un problème métier. |
| Nature | Un service de fourniture de données. | Un produit autonome basé sur des données. |
| Responsabilités | Le fournisseur gère la livraison des données. | L’acheteur du produit est responsable de la gestion et de la maintenance. |
Le Data Fabric
Le Data Fabric adopte une approche complémentaire. Au lieu de transformer l’organisation, il crée une couche d’abstraction « intelligente » au-dessus de l’infrastructure de données existante, qu’elle soit centralisée ou distribuée.
L’objectif du Data Fabric est de connecter et d’automatiser l’accès à des données dispersées en s’appuyant sur les métadonnées actives.
Composants clés d’un Data Fabric :
- Un graphe de connaissances (Knowledge Graph) : Il cartographie dynamiquement tous les actifs de données de l’entreprise, leurs relations, leurs métadonnées et leur lignage.
- Une orchestration et une livraison de données automatisées : Il propose des pipelines de données intelligents et des services de virtualisation pour fournir les données au bon format et au bon endroit, sans intervention manuelle.
- (facultatif) Un moteur de recommandation basé sur l’IA : Il analyse les métadonnées pour suggérer des jeux de données pertinents aux utilisateurs, optimiser les requêtes et automatiser l’intégration.
Le Data Fabric est un « tissu » qui rend l’architecture des données plus intelligente, plus agile et plus facile à utiliser pour les utilisateurs.
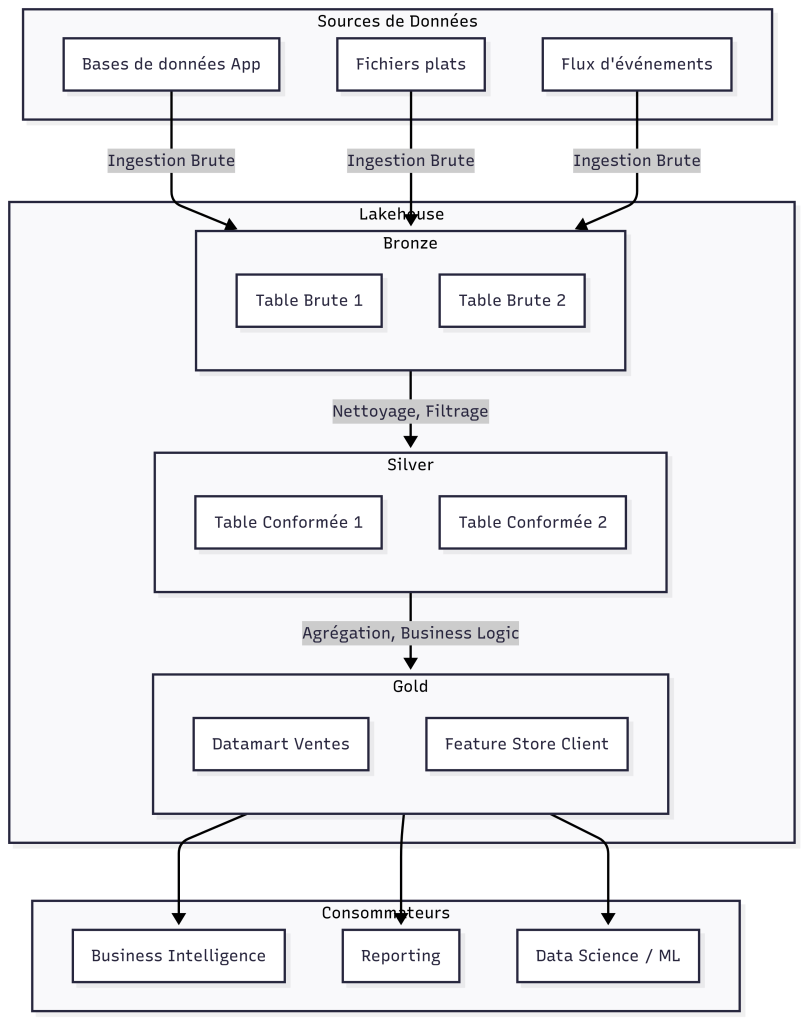
L’architecture Data Lakehouse
Le débat historique entre Data Warehouse et Data Lake a dominé les discussions sur l’analytique pendant des années. Le Data Warehouse, avec sa structure rigide et optimisée pour le SQL, excelle dans la Business Intelligence traditionnelle. Le Data Lake, avec sa capacité à stocker des données brutes et variées à faible coût, est la fondation des cas d’usage de Machine Learning et de Data Science.
L’architecture Data Lakehouse émerge comme une synthèse puissante de ces deux mondes, combinant la flexibilité et le faible coût des Data Lakes avec les performances, la fiabilité et la gouvernance des Data Warehouses.
Les 6 composants modulaires du Lakehouse
Un Lakehouse n’est pas un produit monolithique, mais un assemblage de six composants ou couches logiques qui peuvent être implémentés avec différentes technologies, offrant une grande flexibilité.
- La couche de stockage (Lake Storage) : La fondation du Lakehouse. Il s’agit d’un stockage objet cloud, hautement scalable et économique, comme Amazon S3, Azure Data Lake Storage ou Google Cloud Storage.
- Le format de fichier ouvert (Open File Format) : Les données sont stockées dans des formats de fichiers ouverts et orientés colonne comme Apache Parquet, qui offre une compression efficace et des performances de lecture élevées.
- Le format de table transactionnel (Transactional Table Format) : C’est la pierre angulaire du Lakehouse. Des formats comme Delta Lake, Apache Iceberg ou Apache Hudi ajoutent une couche de métadonnées au-dessus des fichiers Parquet pour apporter des capacités transactionnelles (ACID), le versioning des données (time travel), et une gestion unifiée des données batch et streaming.
- Le moteur de stockage (Storage Engine) : Un moteur optimisé pour l’accès aux données sur le stockage objet, qui gère le partitionnement, l’indexation et la mise en cache pour accélérer les requêtes.
- Le catalogue de données unifié (Unified Catalog) : Un catalogue centralisé (comme Unity Catalog de Databricks ou AWS Glue) qui gère les métadonnées, les permissions et la gouvernance pour tous les actifs du Lakehouse (fichiers, tables, modèles de ML, etc.).
- Les moteurs de calcul (Compute Engines) : Une variété de moteurs de calcul peuvent interagir avec les données du Lakehouse via le format de table, offrant une flexibilité totale :
- Pour le Big Data et l’ETL : Apache Spark.
- Pour la BI et le SQL interactif : Trino ou Presto.
- Pour le Machine Learning : TensorFlow, PyTorch, scikit-learn.
L’approche « médaillon«
Pour organiser les données au sein du Lakehouse, l’architecture Médaillon est une pratique courante. Elle structure les données en trois couches logiques, correspondant à des niveaux croissants de qualité et de transformation.
- La couche Bronze (données brutes) : C’est la zone d’atterrissage des données. Les données y sont ingérées depuis les sources dans leur format original, avec un minimum de transformation. L’objectif est de conserver un historique complet et immuable des données sources.
- La couche Silver (données nettoyées et mise en conformitées) : Les données de la couche Bronze sont nettoyées, filtrées, et mise en conformitées. Les types de données sont standardisés, les valeurs manquantes sont traitées, et les données de différentes sources sont jointes pour créer une vue d’entreprise « propre » et fiable. C’est la source unique de vérité pour les analystes.
- La couche Gold (données agrégées et spécifiques aux cas d’usage) : Les données de la couche Silver sont agrégées et transformées pour répondre aux besoins spécifiques des cas d’usage métiers (BI, reporting, ML). On y trouve des tables de faits et de dimensions, des « feature stores » pour le Machine Learning, etc. C’est la couche optimisée pour la performance et la consommation.
Master Data Management (MDM)
Dans un paysage de données de plus en plus distribué, comment garantir qu’un client, un produit ou un fournisseur signifie la même chose pour tous les départements de l’entreprise ? C’est le défi auquel répond le Master Data Management (MDM).
Le MDM est la discipline qui vise à créer et à maintenir une source unique de vérité, fiable et faisant autorité (Single Source of Truth) pour les entités de données critiques de l’entreprise, appelées « données de référence » ou « master data ».
4.1 Pourquoi le MDM est-il si important ?
Sans MDM, les entreprises souffrent de :
- Incohérence des données : Le même client peut exister avec des adresses ou des noms différents dans le CRM, l’ERP et le système de facturation.
- Mauvaise qualité des rapports : Des rapports basés sur des données incohérentes mènent à des décisions erronées.
- Inefficacité opérationnelle : Les employés perdent un temps précieux à réconcilier manuellement les données entre les systèmes.
- Risques de conformité : Il est difficile de garantir le respect des préférences d’un client (ex: consentement RGPD) si ses données sont fragmentées.
Le MDM est la colonne vertébrale qui assure la cohérence et la fiabilité des données à travers l’ensemble des processus et applications de l’entreprise.
4.2 Les piliers d’une démarche MDM réussie
Une initiative MDM ne se résume pas à l’achat d’un outil. Elle repose sur trois piliers méthodologiques :
- La consolidation : Identifier et regrouper toutes les instances des données de référence dispersées dans les systèmes sources.
- L’harmonisation : Appliquer des règles de nettoyage, de standardisation et de déduplication pour créer un « golden record » unique et fiable pour chaque entité.
- La maintenance et la synchronisation : Mettre en place des processus de gouvernance et des flux de données pour maintenir la qualité des données de référence dans le temps et les synchroniser avec les systèmes opérationnels.
Le Data Catalog d’entreprise
Avec l’explosion du volume et de la variété des données, le plus grand défi n’est plus de les stocker, mais de les trouver, de les comprendre et de leur faire confiance. Le Data Catalog d’entreprise est la solution qui répond à ce défi.
Il agit comme « Google Search » pour les données de l’entreprise, un inventaire qui permet aux utilisateurs (analystes, data scientists, etc.) de découvrir, d’évaluer et d’accéder aux actifs de données dont ils ont besoin.
L’architecture d’un Data Catalog moderne
Un catalogue de données moderne s’articule autour de quatre composants :
- Le référentiel de métadonnées (Metadata Store) : C’est le cœur du catalogue. Il stocke trois types de métadonnées, collectées automatiquement depuis les sources de données :
- Métadonnées techniques : Schémas, types de données, volume, etc.
- Métadonnées opérationnelles : Lignage des données, fraîcheur, logs d’exécution des pipelines.
- Métadonnées métier : Définitions fonctionnelles, propriétaires, tags, niveau de qualité, sensibilité.
- Le moteur de recherche (Search Engine) : Une interface de recherche puissante, similaire à un moteur de recherche web, qui permet aux utilisateurs de trouver des actifs de données en utilisant des mots-clés, des filtres, des tags, etc.
- Le backend : Il gère la collecte des métadonnées (via des connecteurs), l’enrichissement collaboratif (permettant aux utilisateurs d’ajouter des commentaires, des notations, des certifications) et l’application des politiques de gouvernance.
- Le frontend : L’interface utilisateur intuitif qui permet de naviguer dans le catalogue, de visualiser le lignage des données, de comprendre le contexte métier et de demander l’accès aux données.

Le rôle stratégique de l’architecte Data
Les sections précédentes ont détaillé les paradigmes architecturaux modernes — Lakehouse, Data Mesh, Data Fabric. Cependant, une architecture, aussi brillante soit-elle, reste une construction théorique sans le chef d’orchestre capable de la concrétiser, de la gouverner et de la faire évoluer. Ce chef d’orchestre est l’architecte Data.
Le rôle a radicalement évolué. D’un profil technique initialement centré sur la modélisation de bases de données, l’architecte Data est aujourd’hui un partenaire stratégique, un facilitateur et un agent de transformation au carrefour du métier, de la technologie et de la gouvernance. Cette section a pour objectif de répondre à trois questions fondamentales :
- Quoi ? Quelles sont les missions fondamentales de l’architecte Data moderne ?
- Rôle et Responsabilités : Comment son rôle s’adapte-t-il spécifiquement à chaque paradigme architectural ?
- Comment ? Quelle est la démarche pratique et la boîte à outils qu’il emploie pour passer de la stratégie à l’implémentation ?
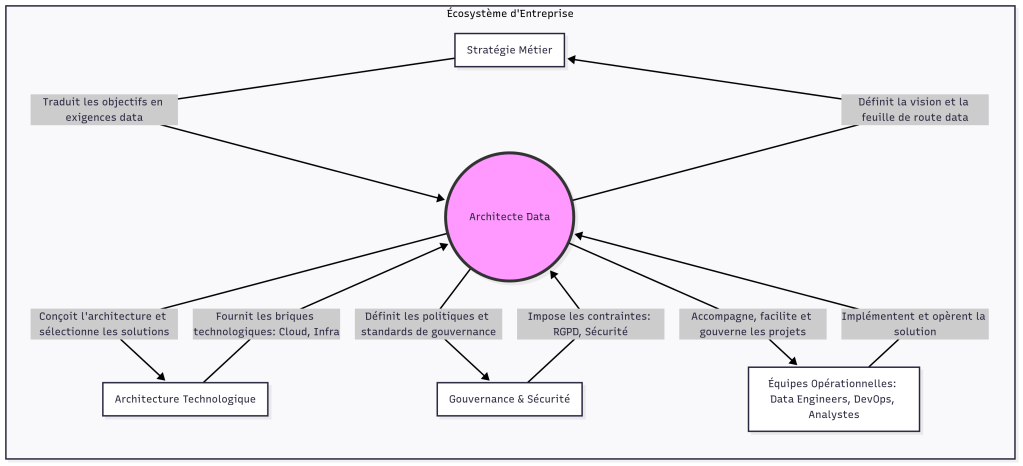
Le positionnement de l’architecte Data
L’architecte Data n’opère pas en silo. Il est le pivot qui connecte la stratégie d’entreprise aux réalités techniques et opérationnelles. Son positionnement est au cœur d’un écosystème complexe, comme l’illustre le schéma ci-dessous.
Les missions fondamentales de l’architecte Data (Le « Quoi »)
Indépendamment du contexte, les missions de l’architecte Data peuvent être regroupées en cinq piliers :
- Traduire la Stratégie métier en « Vision Data » : C’est sa mission première. Il dialogue avec les directions métiers (ou Business analysts) pour comprendre les objectifs business (par exemple : « améliorer l’expérience client de 30% », « lancer un nouveau produit en 6 mois ») et les traduit en une vision data claire et des exigences architecturales. Il garantit l’alignement stratégique en permanence.
- Concevoir l’architecture Data cible : Il conçoit le plan directeur (blueprint) du patrimoine data de l’entreprise. Cela inclut le choix des paradigmes (Lakehouse, Mesh, etc.), la définition des flux de données (traduction des flux information entre les Business capabilities), la sélection des technologies, la modélisation des entités critiques et la conception des plateformes pour le stockage, le traitement et la consommation des données. Pour assumer ses missions, l’architecte Data sera en constante discussion avec ses collègues architectes (Infra et Solution).
- Garantir la gouvernance et la qualité des données : L’architecte ne se contente pas de construire des pipelines ; il s’assure que les données qui y circulent sont fiables, sécurisées et conformes. Il définit les standards, les politiques de qualité, les règles de gestion du cycle de vie des données et collabore avec ses collègues en charge de la données (Data Steward, Data scientist, Data engineer …) pour mettre en place un cadre de gouvernance robuste.
- Faciliter la collaboration et l’accompagnement : Il agit comme un pont entre les équipes. Il accompagne les Data engineers dans l’implémentation, aide les Business analystes à trouver et à comprendre les données, et conseille les chefs de projet sur la manière d’intégrer les exigences data dans leurs feuilles de route.
Rôles et responsabilités par paradigme architectural
Le rôle de l’architecte Data n’est pas monolithique. Il s’adapte en fonction du paradigme architectural choisi. Parce qu’il n’existe toujours pas un seul paradigme implémenté dans une entreprise, mais plusieurs (en fonction de la maturité des équipes gérant les données). L’architecte Data s’adaptera et choisira le paradigme le plus adéquat.
- Dans une architecture Lakehouse :
- Rôle principal : Ingénieur des fondations analytiques.
- Responsabilités clés :
- Concevoir et optimiser l’architecture Médaillon (Bronze, Silver, Gold).
- Sélectionner et standardiser les formats de table (Delta Lake, Iceberg, Hudi) et les moteurs de calcul (Spark, Trino).
- Définir avec les experts, les stratégies d’ingestion (batch, streaming) et d’optimisation du stockage (partitionnement, Z-Ordering).
- Garantir la performance et la rentabilité de la plateforme en équilibrant les coûts de stockage et de calcul.
- Dans une architecture Data Mesh :
- Rôle principal : Facilitateur de l’écosystème fédéré et urbaniste de la Donnée.
- Responsabilités clés :
- Passer d’un « constructeur » à un « facilitateur ». Il ne construit pas tous les produits data lui-même.
- Concevoir et maintenir la plateforme data en libre-service (self-service data platform) qui permet aux domaines de créer et gérer leurs propres produits data.
- Définir les standards globaux d’interopérabilité (formats des ports de sortie, politiques de sécurité, standards de métadonnées) que tous les produits data doivent respecter.
- Évangéliser la culture « Data as a Product » et accompagner les équipes métier (domain teams) dans leur montée en compétence.
- Animer la gouvernance fédérée, en s’assurant que les décisions prises au niveau des domaines restent cohérentes avec la vision globale.
- Dans une architecture Data Fabric :
- Rôle principal : Tisserand des Données connectées et architecte des métadonnées.
- Responsabilités clés :
- Concevoir et enrichir le graphe de connaissances (knowledge graph) qui cartographie les actifs de données, les métadonnées et leurs relations.
- Sélectionner et configurer la technologie de Data Fabric qui automatise la découverte, l’intégration et la livraison des données.
- Définir les politiques d’accès dynamiques basées sur le contexte (rôle de l’utilisateur, sensibilité de la donnée, etc.).
- Orchestrer l’intégration des données via des pipelines automatisés
| Paradigme Architectural | Rôle Principal de l’Architecte Data | Responsabilités Clés |
| Data Lakehouse | Ingénieur des fondations analytiques | Conception de l’architecture Médaillon, optimisation des moteurs et formats, gouvernance centralisée de la performance. |
| Data Mesh | Urbaniste et facilitateur de l’écosystème fédéré | Conception de la plateforme libre-service, définition des standards d’interopérabilité, animation de la gouvernance fédérée. |
| Data Fabric | Tisserand des données connectées | Conception du graphe de connaissances, automatisation des pipelines, définition des politiques d’accès dynamiques. |
La démarche de l’architecte Data (Le « Comment »)
Pour passer de la vision à la réalité, l’architecte Data suit une démarche structurée, itérative et profondément ancrée dans les principes de l’architecture d’entreprise (comme ceux décrits dans TOGAF). Voici une approche pratique en 5 étapes.
Étape 1 : Cadrage et Alignement Stratégique (Le « Pourquoi »)
C’est le point de départ. Aucune ligne de code ne peut être écrite, aucune technologie n’est choisie avant d’avoir une réponse claire à la question : « Quel problème métier cherchons-nous à résoudre avec les données ? ».
- Activités clés :
- Organiser des ateliers avec les dirigeants et les responsables métiers pour capturer les objectifs stratégiques. Cette tâche est généralement déléguée aux business analystes qui auront comme responsabiltés de transférer leurs analyses et informations à l’architecte Data, entre autres.
- Analyser les documents stratégiques de l’entreprise (plans à 3 ans, rapports annuels). Cette tâche est généralement déléguée aux architectes responsables de définir la stratégie du SI. Dans ce cadre, ils aurant la responsabilité de travailler « main dans la main » avec l’architecte Data.
- Identifier les capacités métiers (Business capabilities) qui doivent être créées ou améliorées (cfr business capabilities).
- Définir les principes d’architecture data (ex: « Les données sont partagées par défaut », « Nous favorisons les solutions ouvertes », « La gouvernance est fédérée »).
- Livrables :
- Document de Vision de l’architecture Data.
- Catalogue des principes d’architecture data.
- Cartographie des capacités métiers cibles.
Étape 2 : Analyse de l’Existant (Architecture « As-Is »)
Il est impossible de tracer une route sans connaître le point de départ. Cette étape consiste à cartographier le paysage data actuel pour comprendre ses forces, ses faiblesses et les contraintes héritées.
- Activités clés :
- Inventorier les sources de données existantes (bases de données, applications, fichiers plats, API externes).
- Cartographier les flux de données actuels (« comment l’information circule aujourd’hui ? »).
- Analyser les processus métiers consommateurs et producteurs de données.
- Évaluer la maturité de la gouvernance et de la qualité des données.
- Identifier les « pain points » (points de « douleur ») actuels : silos, redondance, latence, manque de fiabilité.
- Livrables :
- Cartographie de l’architecture data « As-Is » (Baseline Architecture)16.
- Catalogue des sources de données.
- Rapport d’analyse des écarts (Gap Analysis) entre l’existant et les besoins stratégiques17.
Étape 3 : Conception de l’Architecture Cible (« To-Be »)
C’est le cœur de la conception architecturale.
- Activités clés :
- Sélectionner le ou les paradigmes architecturaux les plus adaptés (Lakehouse, Mesh, Fabric, ou une approche hybride).
- Concevoir les modèles de données conceptuels (voire logiques, si nécessaire) pour les entités clés.
- Définir le stack technologique cible (plateformes cloud, bases de données, outils d’ingestion, de transformation, de BI).
- Concevoir les patterns d’architecture réutilisables (ex: pattern d’ingestion de données en streaming, pattern de mise à disposition via API).
- Définir le modèle de gouvernance cible (centralisé, fédéré).
- Livrables :
- Schémas de l’architecture data « To-Be » (Target Architecture).
- Standards technologiques et patterns d’architecture.
- Modèle de gouvernance des données.
Étape 4 : Planification de la Migration et Feuille de Route
Une architecture cible ne se construit pas en un jour. Cette étape consiste à découper la vision en un plan d’action réaliste, itératif et qui délivre de la valeur rapidement. L’architecte Data se positionne en soutien et travaille avec l’architecte Solution.
- Activités clés :
- Décomposer l’architecture cible en lots de travaux (work packages) cohérents.
- Définir des architectures de transition intermédiaires qui constituent des paliers stables et fonctionnels.
- Prioriser les lots de travaux en fonction de la valeur métier, des dépendances techniques et des risques.
- Élaborer une feuille de route (roadmap) pluriannuelle avec des jalons clairs.
- Livrables :
- Feuille de route de la transformation (Architecture Roadmap)23.
- Plan de migration détaillé (pour les premières étapes)24.
- Définition des architectures de transition.
Étape 5 : Gouvernance et Pilotage de l’Implémentation
Le rôle de l’architecte ne s’arrête pas à la conception. Il doit s’assurer que l’implémentation est fidèle à la vision et que l’architecture reste pertinente face aux évolutions.
- Activités clés :
- Mettre en place et animer un comité de revue d’architecture (Architecture Review Board) pour valider la conformité des projets.
- Rédiger des contrats d’architecture (Architecture Building Permit) avec les équipes de projet pour formaliser les attentes.
- Suivre les indicateurs de performance (KPIs) de l’architecture (coût, performance, taux d’adoption, qualité des données).
- Gérer les demandes de changement et les dérogations via un processus formel.
- Assurer une communication continue avec toutes les parties prenantes.
- Livrables :
- Modèle de gouvernance de l’implémentation (Implementation Governance Model).
- Rapports de conformité des projets (Compliance Assessments).
- Tableau de bord des KPIs de l’architecture.
Conclusion
L’architecture Data n’est plus une discipline technique isolée ; elle est au cœur de la stratégie et de la performance de l’entreprise. Des paradigmes comme le Lakehouse, le Data Mesh et le Data Fabric offrent des outils puissants pour construire des écosystèmes de données agiles, scalables et gouvernés.
Cependant, la technologie seule ne suffit pas. Le succès d’une transformation data repose sur la vision et le leadership d’un architecte Data, capable de faire le pont entre le métier et la technique, de traduire les ambitions en plans concrets, et de piloter le changement avec rigueur et pragmatisme.
En adoptant une démarche structurée, inspirée des meilleures pratiques de l’architecture d’entreprise, les organisations peuvent transformer leur patrimoine data d’un centre de coût complexe en un véritable moteur d’innovation et de compétitivité durable.

Laisser un commentaire